Álgebra Lineal en Python con NumPy (I): Operaciones básicas
Introducción
En esta entrada vamos a ver una introducción al Álgebra Lineal en
Python con NumPy. En la mayoría de los artículos que hemos escrito hasta
ahora en Pybonacci hemos tocado sin mencionarlos conceptos relativos al
Álgebra Lineal: sin ir más lejos, el propio manejo de matrices o la
norma de vectores. El lenguaje matricial es el punto de partida para una
enorme variedad de desarrollos físicos y matemáticos, y por eso le
vamos a dedicar un apartado especial para repasar las posibilidades que
ofrece el paquete NumPy.
- Operaciones básicas
- Sistemas, autovalores y descomposiciones
En esta entrada se ha usado python 2.7.3 y numpy 1.6.1 y es compatible con python 3.2.3
Arrays y matrices
Como ya comentamos hace tiempo en nuestra
introducción a Python,
el paquete NumPy introdujo los arrays N-dimensionales, que no son más
que colecciones homogéneas de elementos indexados usando N elementos.
Los hemos utilizado constantemente usando las
funciones de creación de arrays:
In [1]: import numpy as np
In [2]: np.array([1, 2, 3]) # Array de una lista
Out[2]: array([1, 2, 3])
In [3]: np.arange(5) # Array de 5 enteros contando el 0
Out[3]: array([0, 1, 2, 3, 4])
In [4]: np.zeros((2, 3)) # Array de ceros de 2x3
Out[4]:
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
In [5]: np.linspace(0.0, 1.0, 5) # Discretización de [0, 1] con 5 puntos
Out[5]: array([ 0. , 0.25, 0.5 , 0.75, 1. ])
Además de los arrays, con NumPy también podemos manejar matrices.
Aunque parecen lo mismo, se utilizan de manera distinta; si alguien
quiere investigar las diferencias, puede consultar la página
NumPy para usuarios de MATLAB (en inglés).
Nota: Aunque la traducción al castellano de array
sería precisamente vector, para evitar confusión voy a seguir utilizando
la palabra inglesa, como he venido haciendo desde que se creó el blog.
Si queremos matrices, entonces hemos de usar la función
matrix:
In [17]: v2 = np.matrix([0, 1, 2, 3])
In [18]: v2
Out[18]: matrix([[0, 1, 2, 3]])
In [19]: np.transpose(v2)
Out[19]:
matrix([[0],
[1],
[2],
[3]])
In [20]: v2.T
Out[20]:
matrix([[0],
[1],
[2],
[3]])
In [27]: np.matrix(""" # Para los nostálgicos
....: 1, 2;
....: 3, 4
....: """)
Out[27]:
matrix([[1, 2],
[3, 4]])
Las ventajas de usar matrices en el fondo son muy pocas y además la
mayoría de funciones de NumPy maneja arrays, así que tendrías que
convertir entre ambos tipos constantemente. Hoy mostraremos brevemente
el uso de las matrices también, pero mejor utilizar arrays y olvidarse

Operaciones básicas, expansión
Suma
La suma de arrays y de matrices es igual: se realiza elemento a elemento. El producto por un escalar tampoco tiene misterio:
In [1]: import numpy as np
In [2]: a = np.array([[1, 2], [3, 4]])
In [3]: a + a
Out[3]:
array([[2, 4],
[6, 8]])
In [4]: m = np.matrix([[1, 2], [3, 4]])
In [5]: m + m
Out[5]:
matrix([[2, 4],
[6, 8]])
In [6]: a + m # Podemos sumar arrays y matrices
Out[6]:
matrix([[2, 4],
[6, 8]])
In [7]: 2 * a # Producto por un escalar
Out[7]:
array([[2, 4],
[6, 8]])
In [8]: -m
Out[8]:
matrix([[-1, -2],
[-3, -4]])
Expansión o «broadcasting»
Si los objetos que estamos operando no tienen las mismas dimensiones,
NumPy puede adaptar algunas de ellas para completar la operación. Esto
se denomina
broadcasting en inglés, y a falta de una traducción mejor y a menos que alguien tenga algo que objetar lo voy a denominar «
expansión». Porque yo lo valgo.
NumPy alinea los arrays a la derecha y empieza a comprobar las
dimensiones por el final. Si son todas compatibles realiza la operación,
y si no lanza un error. Dos dimensiones son compatibles si
- Son iguales, o
- Una de ellas es 1.
Si los objetos no tienen el mismo número de dimensiones, se asume que
las restantes son 1. Si dos dimensiones son distintas pero compatibles,
la menor se
expande hasta tener el tamaño de la mayor. Vamos a ver un par de ejemplos:
In [29]: c = np.zeros((3, 3))
In [30]: c
Out[30]:
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
In [31]: c.shape
Out[31]: (3, 3)
In [32]: n = np.array([1, 2, 3])
In [33]: n
Out[33]: array([1, 2, 3])
In [34]: n.shape
Out[34]: (3,)
In [35]: n + c # Se expande la primera dimensión de n
Out[35]:
array([[ 1., 2., 3.],
[ 1., 2., 3.],
[ 1., 2., 3.]])
In [61]: xx = np.arange(4)
In [62]: yy = np.arange(4).reshape((4, 1))
In [63]: xx
Out[63]: array([0, 1, 2, 3])
In [64]: xx.shape
Out[64]: (4,)
In [65]: yy
Out[65]:
array([[0],
[1],
[2],
[3]])
In [66]: yy.shape
Out[66]: (4, 1)
In [67]: xx + yy * 1j # Se expanden la segunda dimensión de y y la primera de x
Out[67]:
array([[ 0.+0.j, 1.+0.j, 2.+0.j, 3.+0.j],
[ 0.+1.j, 1.+1.j, 2.+1.j, 3.+1.j],
[ 0.+2.j, 1.+2.j, 2.+2.j, 3.+2.j],
[ 0.+3.j, 1.+3.j, 2.+3.j, 3.+3.j]])
Como podéis ver, esto abre un mundo de posibilidades. Si queréis
ampliarlas, podéis consultar el material de donde he sacado esto en la
página
Broadcasting de la guía del usuario de NumPy.
Producto
En el producto es donde surgen las diferencias fundamentales entre
arrays y matrices. Mientras que con los arrays el producto se hace
elemento a elemento (y si las dimensiones no coinciden se expanden como
hemos visto antes), el producto de matrices tiene, como ya sabemos, una
definición totalmente distinta.
Para el
producto matricial:
In [69]: a = np.array([[1, 0], [2, -1]])
In [70]: a
Out[70]:
array([[ 1, 0],
[ 2, -1]])
In [71]: np.dot(a, a)
Out[71]:
array([[1, 0],
[0, 1]])
In [72]: m = np.matrix('1 0; 2 -1')
In [73]: m
Out[73]:
matrix([[ 1, 0],
[ 2, -1]])
In [74]: m * m
Out[74]:
matrix([[1, 0],
[0, 1]])
Y para el
producto elemento a elemento
In [80]: a
Out[80]:
array([[ 1, 0],
[ 2, -1]])
In [81]: a * a
Out[81]:
array([[1, 0],
[4, 1]])
In [82]: m
Out[82]:
matrix([[ 1, 0],
[ 2, -1]])
In [83]: np.multiply(m, m)
Out[83]:
matrix([[1, 0],
[4, 1]])
Nótese que con las matrices el producto «por defecto» es el producto tal y como lo conocemos en Álgebra Lineal.
Ya hemos utilizado
la función dot, que realiza un producto escalar entre sus dos argumentos, en este caso generalizado para matrices. NumPy también ofrece
la función inner,
que no es más que producto interior. Matemáticamente, el producto
escalar es un caso particular del interior; en NumPy, ambos son
idénticos para objetos de dimensión menor o igual que 2. Para arrays de
dimensiones mayores que 2, se diferencian en las dimensiones sobre las
que se suma.
Con NumPy podemos calcular también el producto vectorial y el producto exterior de dos vectores, utilizando las funciones
cross y
outer respectivamente:
In [102]: u = np.arange(3)
In [103]: v = 1 + np.arange(3) # ¡Expansión sobre el 1!
In [104]: u
Out[104]: array([0, 1, 2])
In [105]: v
Out[105]: array([1, 2, 3])
In [106]: np.cross(u, v) # Producto vectorial
Out[106]: array([-1, 2, -1])
In [107]: np.outer(u, v) # Producto exterior
Out[107]:
array([[0, 0, 0],
[1, 2, 3],
[2, 4, 6]])
Norma y determinante
NumPy ofrece también diversas funciones para calcular la norma y el
determinante de un array. Para calcular el determinante de un array de
dimensión 2 utilizamos la función
linalg.det. También podemos conocer la traza con la función
trace:
In [111]: a
Out[111]:
array([[ 1, 0],
[ 2, -1]])
In [112]: np.linalg.det(a)
Out[112]: -1.0
In [113]: np.trace(a)
Out[113]: 0
Con NumPy podemos obtener también la norma de un array de cualquier
dimensión y el número de condición de un array bidimensional. Para ello
utilizamos las funciones
linalg.norm y
linalg.cond respectivamente, que aceptan un segundo argumento: el tipo de norma utilizado. Así, podemos conocer la norma-2 de un vector
||v||2 o la norma infinito o del supremo de una matriz
||A||infty. Para una lista completa, puedes consultar la documentación.
In [121]: a
Out[121]:
array([[ 1, 0],
[ 2, -1]])
In [122]: np.linalg.norm(a)
Out[122]: 2.4494897427831779
In [123]: np.linalg.norm(a, np.inf)
Out[123]: 3
In [124]: np.linalg.norm(a, 1)
Out[124]: 3
In [125]: v
Out[125]: array([1, 2, 3])
In [126]: np.linalg.norm(v)
Out[126]: 3.7416573867739413
In [127]: np.linalg.norm(v, np.inf)
Out[127]: 3
In [128]: np.linalg.norm(v, 1)
Out[128]: 6
In [129]: np.linalg.norm(v, -np.inf)
Out[129]: 1
In [130]: np.linalg.cond(a)
Out[130]: 5.828427124746189
In [131]: np.linalg.cond(a, np.inf)
Out[131]: 9.0
Convenio de Einstein
Finalmente, y como regalo a los que hayan llegado hasta aquí abajo, os enseñamos que con NumPy podemos utilizar el
convenio de sumación de Einstein, utilizando la función
einsum.
Para los que conozcan un poco de álgebra tensorial, esta función les va
a encantar: con ella podemos hacer todo lo que hemos visto
anteriormente y mucho más. En la documentación viene explicado
detenidamente cómo utilizarla y hay unos cuantos ejemplos; vamos a ver
algunos:
In [135]: a
Out[135]:
array([[ 1, 0],
[ 2, -1]])
In [136]: np.trace(a)
Out[136]: 0
In [137]: np.einsum('ii', a) # Traza
Out[137]: 0
In [138]: np.diag(a)
Out[138]: array([ 1, -1])
In [139]: np.einsum('ii -> i', a) # Diagonal
Out[139]: array([ 1, -1])
In [140]: np.dot(a, a)
Out[140]:
array([[1, 0],
[0, 1]])
In [142]: np.einsum('ij, jk', a, a) # Producto matricial
Out[142]:
array([[1, 0],
[0, 1]])
In [143]: u = np.array([1, -2])
In [144]: u
Out[144]: array([ 1, -2])
In [145]: np.dot(a, u)
Out[145]: array([1, 4])
In [146]: np.einsum('ij, j', a, u) # Matriz por vector
Out[146]: array([1, 4])
In [147]: np.dot(u, u)
Out[147]: 5
In [151]: np.einsum('i, i', u, u) # Producto escalar por sí mismo
Out[151]: 5
In [153]: np.outer(u, u)
Out[153]:
array([[ 1, -2],
[-2, 4]])
In [154]: np.einsum('i, j', u, u) # Producto exterior
Out[154]:
array([[ 1, -2],
[-2, 4]])
Las posibilidades que esto ofrece son enormes. Puedes probar a jugar
con tensores de mayor orden, como por ejemplo el símbolo de Levi-Civita.
https://gist.github.com/2689795






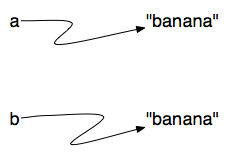 ou
ou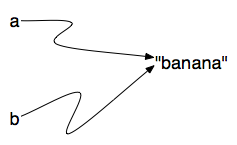 Em uma das interpretações
Em uma das interpretações 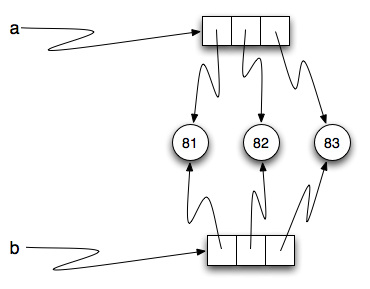
 Como a mesma lista tem dois nomes diferentes,
Como a mesma lista tem dois nomes diferentes, 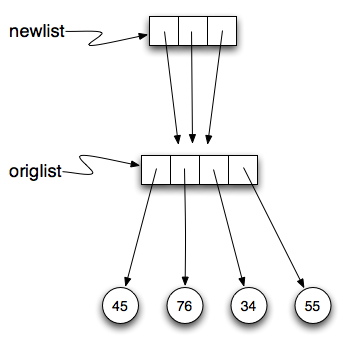 Agora, o que acontece se modificamos um valor da
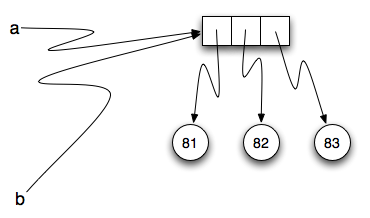
Agora, o que acontece se modificamos um valor da 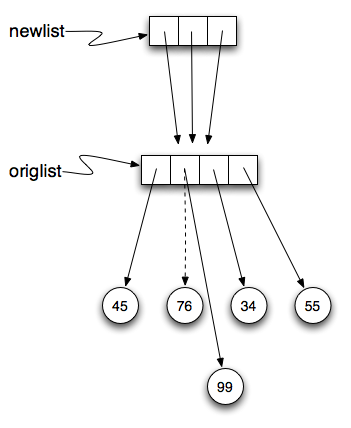 Aqui está o mesmo exemplo no codelens.
Execute o código passo a passo e preste particular atenção
à execução do comando de atribuição
Aqui está o mesmo exemplo no codelens.
Execute o código passo a passo e preste particular atenção
à execução do comando de atribuição 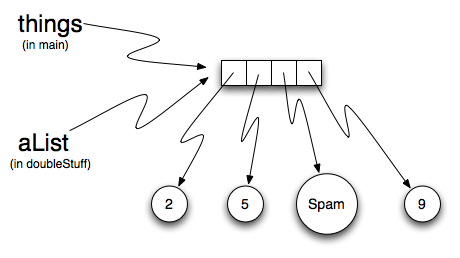 Como a lista de objetos é compartilhada por duas referências,
existe apenas uma cópia. Se a função modifica os elementos da lista
parâmetros, o função que fez a chamada também enxerga as alterações,
já que as alterações estão ocorrendo no original.
Como a lista de objetos é compartilhada por duas referências,
existe apenas uma cópia. Se a função modifica os elementos da lista
parâmetros, o função que fez a chamada também enxerga as alterações,
já que as alterações estão ocorrendo no original.