Raspberry Pi. A fun, hands-on deep learning project for beginners, students, and hobbyists
Implementing real-time deep learning on the Raspberry Pi
Now that we have reviewed our project structure, let’s go ahead and get started.
Open up
pokedex.py
and insert the following code:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.models import load_model
from imutils.video import VideoStream
import numpy as np
import imutils
import json
import time
import cv2
import os
Lines 2-10 handle importing packages for this project.
Notably, we’ll be using Keras’
load_model
to load our pre-trained deep learning model (upon which we’ll make predictions). We’ll be utilizing
VideoStream
from my very own imutils package to handle our live video stream.
Each of the requirements are installable via pip except for OpenCV and TensorFlow (a backend for Keras). Refer to “Configuring your Raspberry Pi for deep learning” section above for any package installs.
Moving on, let’s review our
CONFIG
dictionary:
A fun, hands-on deep learning project for beginners, students, and hobbyists
, contains the path to our input deep learning model. Today we’re using the
pokedex.model
(trained two weeks ago) which resides in the assets directory.
Next,
"labels"
is our set of class labels which our Keras deep learning model was trained to recognize in our previous post.
I actually pasted these values from the terminal Python interpreter shown above for readability and compatibility (rather than loading the pickle file and inserting into the dictionary programmatically).
How come?
Python 2.7 and Python 3 handle pickle files differently (try to deserialize a Python 3 pickle file in a Python 2.7 environment and you’ll see).
To overcome this Python 2.7 and and Python 3 issue, I simply hardcoded the dictionary in the script. An alternative would be loading a text or JSON file of class labels as well.
Let’s check out the rest of the
CONFIG
dictionary:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# define the path to the JSON database of Pokemon info
In this block, we’ve have four more keys + values:
"db_path"
: The path to the Pokemon JSON database which contains information we’ll be displaying about the little critters.
"display_for"
: The number of frames our Pokemon information will be displayed for upon successful classification. I’ve set this value to 240 frames.
"pdx_bg"
: Our Pokedex background GUI image path.
"pdx_mask"
: The GUI’s associated mask image path.
The remaining keys + values in our configuration dictionary are a selection of image coordinates and the text color:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# (x, y)-coordinates of where the video stream location lives
"pdx_vid_x": 25,
"pdx_vid_y": 125,
# (x, y)-coordinates of where the Pokemon's name, height, and
# weight will be drawn
"pdx_name_x": 400,
"pdx_name_y": 167,
"pdx_height_x": 400,
"pdx_height_y": 213,
"pdx_weight_x": 485,
"pdx_weight_y": 213,
# color of all text drawn on the Pokedex
"pdx_color": (33, 33, 42)[::-1]
}
To determine the exact (x, y)-coordinates of where the video stream for the user interface should be displayed, I opened up
pokedex_bg.png
in Photoshop and examined the coordinates.
I found that
(25, 125)
is the appropriate location.
You can use whatever tool you are familiar with, I just use Photoshop regularly and am familiar with the interface.
Similarly, Lines 40-45 define the (x, y)-coordinates for where the Pokemon’s name, height, and weight information will be displayed (again, these coordinates were also determined by examining
pokedex_bg.png
in Photoshop).
The value associated with the
"pdx_color"
key is the RGB tuple of the color we are going to use when drawing the Pokemon name, height, and weight on the user interface. We define this color as RGB tuple and then reverse it since OpenCV expects colors to be passed in using BGR ordering.
Going forward, be sure to refer to the
CONFIG
dictionary as needed.
Next, I’ll initialize some important variables and explain what each represents:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# initialize the current frame from the video stream, a boolean used
# to indicated if the screen was clicked, a frame counter, and the
# predicted class label
frame = None
clicked = False
counter = 0
predLabel = None
The first variable,
frame
, is the current frame captured from the video stream.
Following is
clicked
— a boolean indicating if the screen was tapped (it is a touch screen after all, but your mouse will also work). In a previous PyImageSearch tutorial, I demonstrated how to capture mouse click events with OpenCV — we’ll be using a similar method here. When a user clicks/taps in our application we’ll classify the input frame and display the results for a set amount of time (240 frames in my case).
The
counter
variable holds a count of the number of frames a Pokemon’s information has been displayed for after a classification. We’ll be comparing the value to
CONFIG["display_for"]
to determine if we are finished displaying a result.
The predicted class label (Pokemon species) will be held in
predLabel
— it is initialized to
None
for now.
To handle the clicking/tapping on the user interface, OpenCV requires us to define a callback function. Our
on_click
callback method is defined below:
A fun, hands-on deep learning project for beginners, students, and hobbyists
defon_click(event, x, y, flags, param):
# grab a reference to the global variables
global frame, clicked, predLabel
# check to see if the left mouse button was clicked, and if so,
# perform the classification on the current frame
if event == cv2.EVENT_LBUTTONDOWN:
predLabel = classify(preprocess(frame))
clicked = True
The
on_click
callback function is executed each time a click is captured by the GUI. We’re only concerned with the click event parameter; however, OpenCV provides additional information such as the (x, y)-coordinates, flags, and param.
When our callback function encounters a left mouse click or a finger tap (
event == cv2.EVENT_LBUTTONDOWN
), we
preprocess
and
classify
our
frame
, storing the result as
predLabel
and marking
clicked
as
True
. As denoted by Line 61,
frame
,
clicked
, and
predLabel
are global variables.
The
preprocess
steps must be identical to the steps taken when training our model (you can learn how we trained our Keras deep learning model in an earlier post in the series).
Below you can find the
preprocess
method:
A fun, hands-on deep learning project for beginners, students, and hobbyists
defpreprocess(image):
# preprocess the image
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# return the pre-processed image
return image
In this method, our first step is to
resize
the frame/
image
to
(96, 96)
pixels. Since our model is designed for these dimensions, we must use the same dimensions.
Next, we scale the image pixel array values to the range of
[0, 1]
.
Subsequently, we call
img_to_array
on the image which orders the channels of the array properly, based on “channels first” or “channels last” ordering.
We train/classify images in batches. After calling
np.expand_dims
on the image, it will have the shape
(1, 96, 96, 3)
. Forgetting to add in this extra dimension will result in an error when calling our
predict
method of the model in the
classify
function.
Lastly, we return the
image
to the calling function.
Note: Do the the preprocessing steps of the
preprocess
function look foreign to you? Preprocessing is essential to all deep learning workflows. I cover preprocessing in depth inside of Deep Learning for Computer Vision with Python (along with many more topics that will take you from beginner to seasoned expert throughout the course of the book bundles). Be sure to check out the free sample chapters available here.
Our final helper function,
classify
, accepts an input
image
(making the assumption that it has already been pre-processed) and then classifies it:
A fun, hands-on deep learning project for beginners, students, and hobbyists
defclassify(image):
# classify the input image
proba = model.predict(image)[0]
# return the class label with the largest predicted probability
return CONFIG["labels"][np.argmax(proba)]
Our classify function is very direct and to the point, but this is actually where all the magic happens under the hood.
Calling
model.predict
on the image and grabbing the zero-index result (the results for the first and only image in the batch) returns a list of each of probabilities from the softmax layer in our network (Line 81).
Taking the index of the maximum probability and feeding it into our labels list (in
CONFIG
) yields the human readable class label (Line 84). We then return this label to the calling function.
Now that our helper functions are defined we can move on to creating the user interface:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# load the pokedex background image and grab its dimensions
print("[INFO] booting pokedex...")
pokedexBG = cv2.imread(CONFIG["pdx_bg"])
(bgH, bgW) = pokedexBG.shape[:2]
# load the pokedex mask (i.e., the part where the video will go and)
We first load our user interface image from disk and extract the height and width (Lines 88 and 89).
From there we load the mask image from disk (Line94)and convert it to a single channel grayscale image (Line 95).
We then apply a binary threshold (Lines 96 and 97). After thresholding, the image will only contain 0’s and 255’s (0 for black background and 255 for white foreground).
Moving on, let’s load data, initialize objects, and setup our callback function:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# load the trained convolutional neural network and pokemon database
print("[INFO] loading pokedex model...")
model = load_model(CONFIG["model_path"])
db = json.loads(open(CONFIG["db_path"]).read())
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# setup the mouse callback function
cv2.namedWindow("Pokedex")
cv2.setMouseCallback("Pokedex", on_click)
We load the Pokedex CNN model on Line 100 and the Pokemon database on Line 101.
Then, we initiate our
VideoStream
object. I’m using the PiCamera as is shown on Line 106. If you’re running the app on your laptop/desktop, you can comment this line out (Line 106) and uncomment Line 105.
We pause for
2.0
seconds to allow for the camera to warm up (Line107).
From there, we need to setup the mouse callback listener function. In order to do accomplish this, we first need a
namedWindow
. I named the window
"Pokedex"
on Line 110 and then established the mouse callback on Line 111.
Let’s begin processing frames in a
while
loop:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# loop over the frames from the video stream
whileTrue:
# if the window was clicked "freeze" the frame and increment
# the total number of frames the stream has been frozen for
if clicked and count < CONFIG["display_for"]:
count += 1
else:
# grab the frame from the threaded video stream and resize
# it to have a maximum width of 260 pixels
frame = vs.read()
frame = imutils.resize(frame, width=260)
(fgH, fgW) = frame.shape[:2]
# reset our frozen count, clicked flag, and predicted class
# label
count = 0
clicked = False
predLabel = None
Inside of the
whileTrue
loop, we first check to see if we are currently displaying a classification (Lines 117-118) and if so, increment the
count
variable. In other words, if this if statement is triggered, the frame won’t change up until the number of
CONFIG["display_for"]
frames.
Otherwise, let’s grab a new
frame
from the video stream process it. First we resize it and extract the dimensions (Lines 124 and 125). We also reset
count
,
clicked
, and
predLabel
(Lines 129-131).
Going back to the main execution flow of the loop, we create the actual user interface from the frame:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# create the pokedex image by first allocating an empty array
# with the same dimensions of the background and then applying
array with same dimensions as the background image (Line 136).
Then, we store the
frame
in the
pokedex
array using the coordinates specified from our configuration dictionary on Lines 137 and 138. Essentially, this puts the frame where the white box resides in Figure 9.
We now have a masking trick to perform. The goal of the next two lines is to achieve rounded corners like the white box in Figure 9.
To accomplish the rounding of corners, we first compute the
bitwise_and
between the
pokedex
image and the
pokedexMask
(Line144). This produces round corners and removes any frame content that falls outside the viewport of the mask.
Then, the
bitwise_or
is taken to combine both the
pokedex
and
pokedexBG
to form the final user interface image (Line 145). This
bitwise_or
only works because the
pokedexBG
has a value of 0 (black) for the screen viewport region.
is populated with a class label, we’re going to draw the class label text and lookup other relevant information in our Pokemon database JSON file to display.
Lines 151-153 handle drawing the Pokemon species text (also known as the CNN class label).
Similarly Lines 156-158 and Lines 161-163 handle drawing the Pokemon’s height and width respectively.
Let’s show the output frame and perform cleanup:
A fun, hands-on deep learning project for beginners, students, and hobbyists
# show the output frame
cv2.imshow("Pokedex", pokedex)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
print("[INFO] shutting down pokedex...")
cv2.destroyAllWindows()
vs.stop()
On Line 166 we display the result of our hard work in the
"Pokedex"
named window.
We grab keypresses (Line 167) and if the
"q"
key has been pressed, we
break
out of the loop (Lines 170 and 171).
Upon exiting the while loop, we perform cleanup (Lines 175 and 176) and exit the script.
Real-time deep learning results
We are now ready to see our real-time deep learning application on the Raspberry Pi in action!
Make sure you use the “Downloads” section of this blog post to download the source code.
From there, open up a shell and execute the following command:
A fun, hands-on deep learning project for beginners, students, and hobbyists
$ python pokedex.py
Using TensorFlow backend.
[INFO] booting pokedex...
[INFO] loading pokedex model...
[INFO] starting video stream...
[INFO] shutting down pokedex...
If you’re using a Raspberry Pi to run this code it may take 20-30 seconds to initialize TensorFlow and import the Keras model itself.
Be patient!
Once the model is loaded into memory you’ll be able to perform deep learning image classification in real-time.
A full demo of the Pokedex + real-time deep learning model in action can be found below:
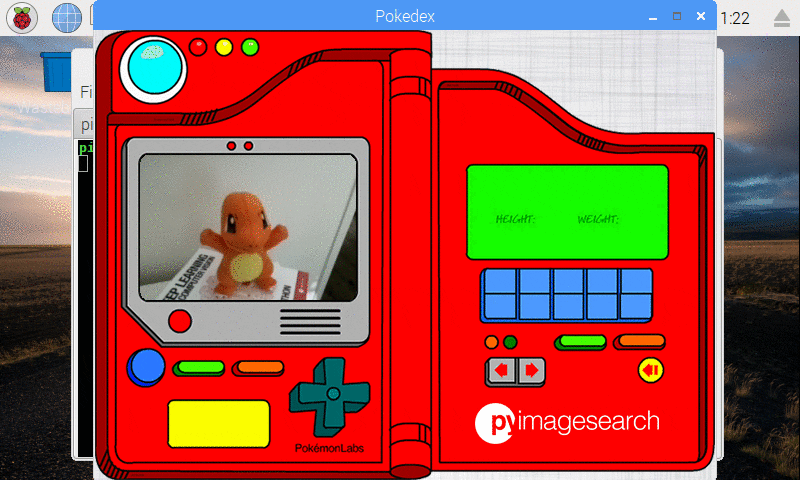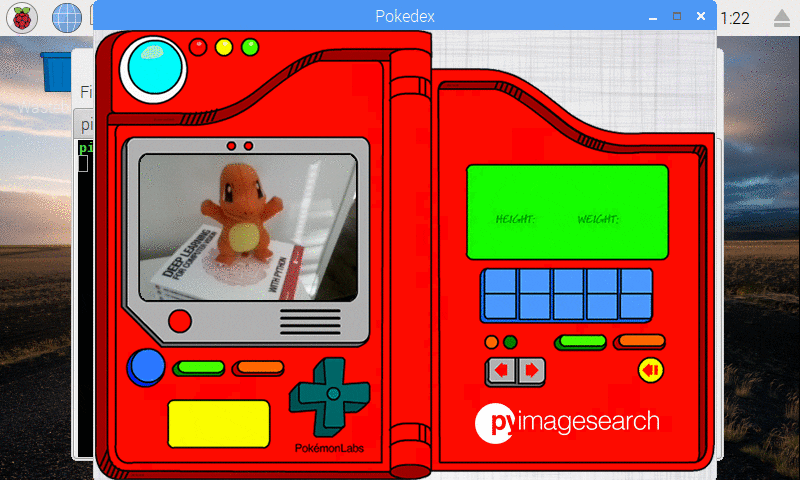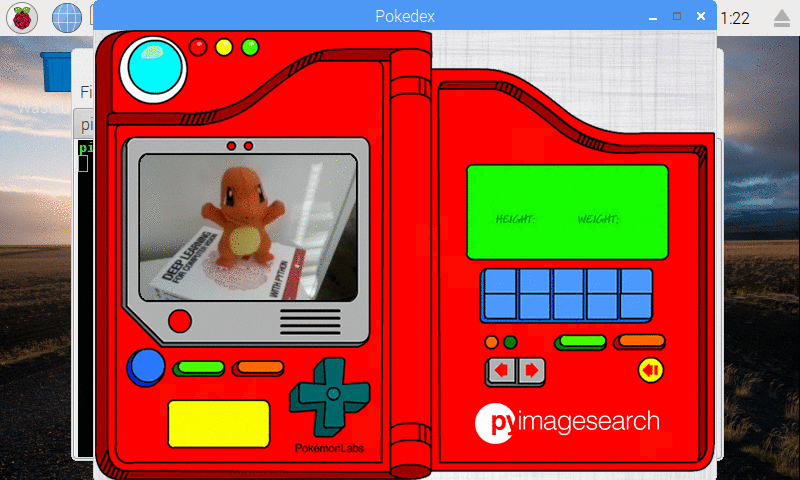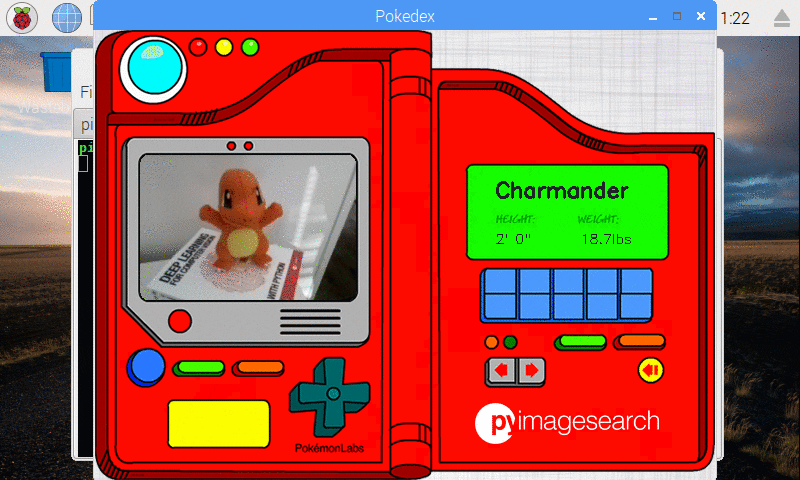
I also created a simple Python script (that ran in the background) to take a screenshot every two seconds — I pieced the screenshots together to form an animated GIF of classifying Charmander:
Figure 10: Our deep learning Pokedex project correctly recognizes Charmander.
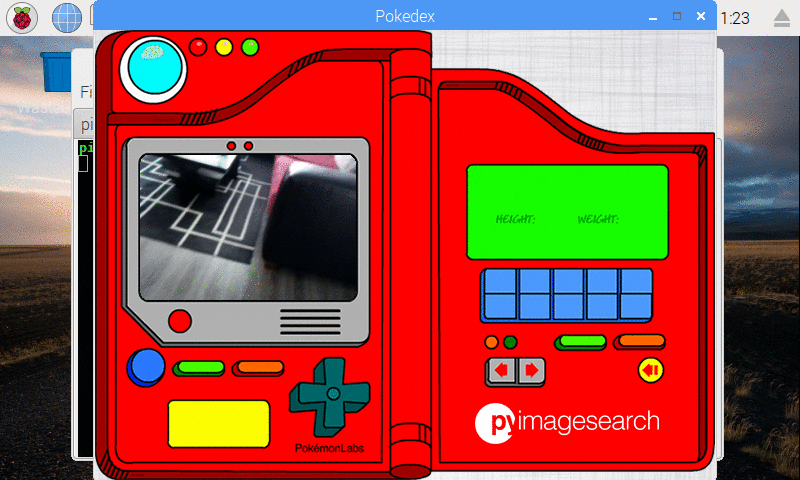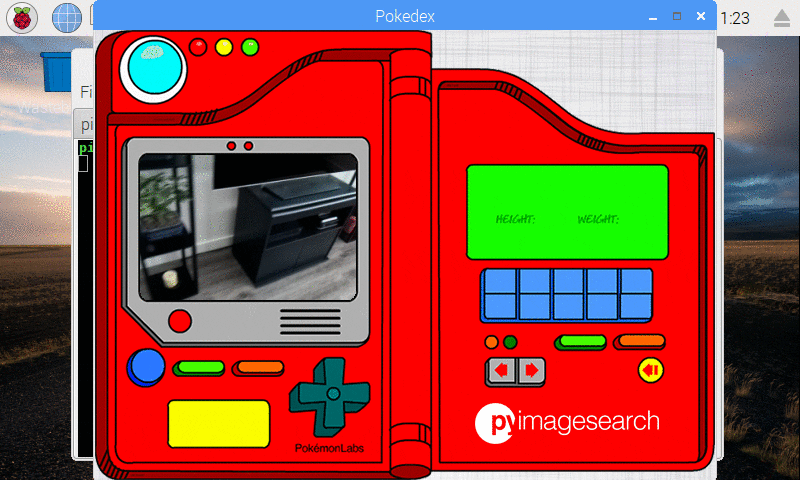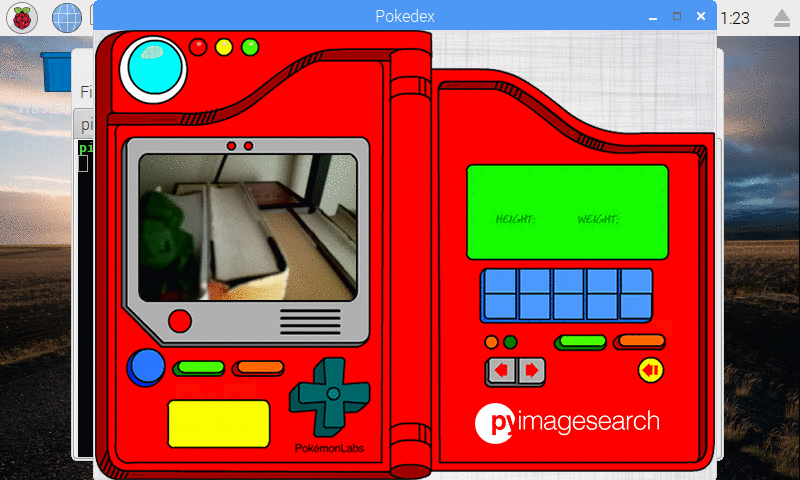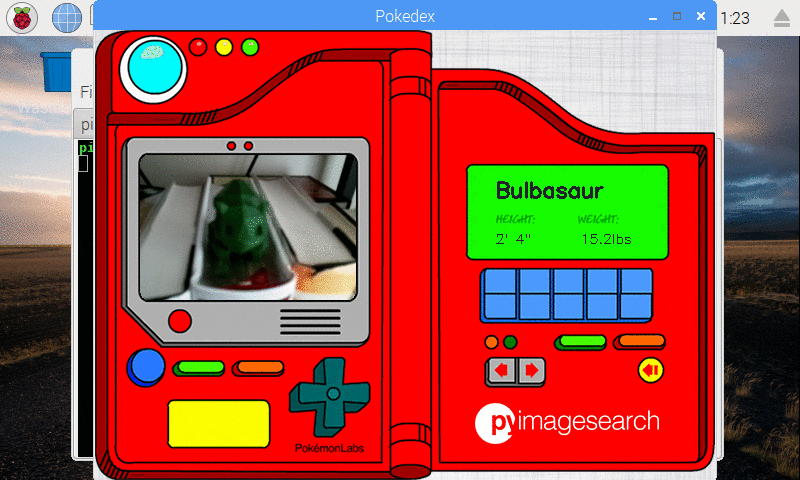
In my Pokemon collection, I have a 3D printed Bulbasaur that I decided to classify as well:
Figure 11: Our Keras CNN is capable of recognizing a 3D printed Bulbasuar!
No hay comentarios:
Publicar un comentario