https://vincentblog.xyz/posts/conceptos-basicos-sobre-redes-neuronales
October 30, 2018
Conceptos básicos sobre redes neuronales
En este post explicaré conceptos básicos sobre redes neuronales. Algunos de los conceptos ya lo he explicado a lo largo de los tutoriales. Los nombres estan en Ingles ya que es más comun encontrarlos de esta manera. Algunos de los conceptos se pueden aplicar a otros modelos de machine learning.
Layer
Existen tres tipos de capas (layers) en una red neuronal, todas contienen una o más neuronas:
- Capa de entrada (Input Layer): Esta capa contiene neuronas que representan los datos que la red neuronal usara para entrenar. El numero de neuronas de esta capa depende del numero de caracteristicas que tengan los datos.
- Capa oculta (Hiden Layer): Una red neuronal puede tener varias capas de este tipo, cada una de estas capas contiene neuronas, en una red neuronal tradicional cada una de las neuronas de una capa estan conectadas con todas las neuronas de la siguiente capa.
- Capa de salida (Output Layer): Esta capa es la que se encarga de entregar los resultados, si estamos resolviendo un problema de clasificación esta capa tendra un numero de neuronas igual al numero de clases que existan en los datos. El resultado es una lista de probabilidades para cada clase.
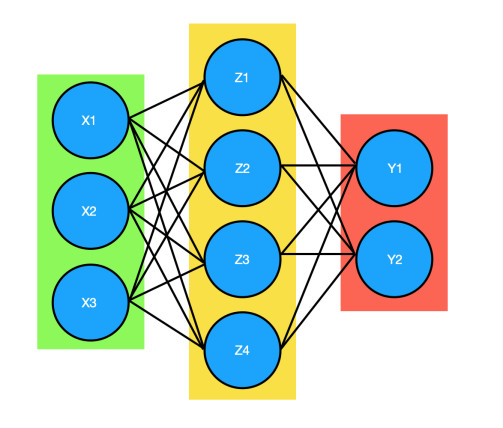
- Verde: Capa de entrada
- Amarilla: Capa oculta
- Roja: Capa de salida
Neuron
Una neurona o nodo es una parte importante de las redes neuronales y pueden haber muchas de ellas repartidas entre varias capas (layers).
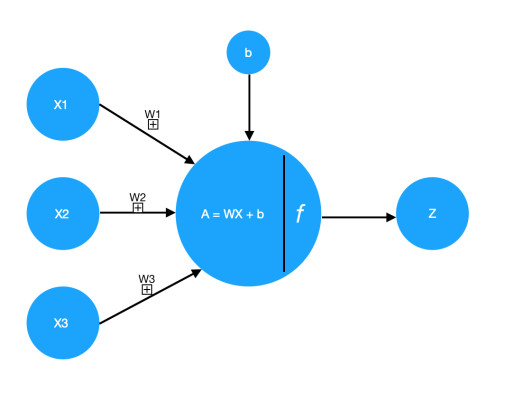
Cada neurona contiene la función:
Z = WX + bEsta función genera una línea que puede dividir los datos en dos grupos:

El resultado de esta función es enviado a la función de activación:
A = sigmoid(Z)
A = relu(Z)y el resultado final (A) es enviado a las neuronas de la siguiente capa(layer) o a la función de perdida.
Cada neurona tiene diferentes pesos (W) y un parametro b que es igual entre las neuronas de una misma capa.
Una neurona recibe un parametro X que pueden ser los datos de entrada o los datos de salida de una neurona de la capa anterior.
Overfitting
Este concepto se aplica cuando la red neuronal aprende mucho sobre los datos de entrenamiento pero tiene un desempeño pobre en los datos de validación o en datos que nunca ha visto. Este comportamiento siempre lo queremos evitar.
Underfitting
Este concepto es lo contrario de overfitting. Sucede cuando la red neuronal no aprendió correctamente sobre los datos de entrenamiento y en general tiene un desempeño muy pobre en todas las predicciones.
Training set
Cuando tenemos un set de datos (también le podemos llamar agrupación de datos) es importante dividirlo en dos o tres sets diferentes, el primero de ellos es el set de entrenamiento, este es el set que se usa para que la red neuronal aprenda patrones sobre los datos, en código se suele expresar de la siguiente manera:
X_train
y_trainValidation set
Este es el segundo set de datos. Es necesario que este set tenga datos diferentes de los otros dos sets, esto es importante ya que queremos ver que tan buena es la red neuronal en datos que nunca ha visto.
Este set se usa para buscar los mejores hiperparametros de una red neuronal, pueden ser: learning rate, epochs, optimizer, batch_size, numero de capas, numero de nodos, funciones de activación, etc. Queremos entrenar a la red neuronal con ciertos hiperparametros, ver el resultado en el set de validación, cambiar los valores de los hiperparametros e ir comparando resultados hasta encontrar los hiperparametros que sean buenos resolviendo el problema.
No se deben de confundir con los parametros W y b, estos dos parametros se modifican internamente en la red neuronal con el algoritmo de backpropagation.
en código se expresa de la siguiente manera:
X_val
y_valTest set
Este es el ultimo set de datos que se tiene en cuenta cuando se entrena una red neuronal. Este set se usa al final para comprobar que tan buena es la red neuronal despues de entrenarla y encontrar los mejores hiperparametros.
Si no tenemos muchos datos este set se puede ignorar y solo quedarnos con el set de entrenamiento y el set de validación.
En código se expresa de la siguiente manera:
X_test
y_testForwardpropagation
Es la manera en la cual las redes neuronales crean las predicciones. En un principio la red neuronal tiene valores de W y b aleatorios en cada neurona, los datos de entrenamiento pasan por estas neuronas hasta llegar a la capa de salida, en esta capa la red neuronal predice la clase a la cual pertenecen los datos de entrenamiento, estas predicciones las usa la función de perdida para medir que tan buena es la red neuronal, este ciclo se repite varias veces segun indiquemos y en cada ciclo se ejecuta el algoritmo de backpropagation para actualizar los valores de W y b.
Backpropagation
Es importante conocer este concepto a detalle, generalmente se conoce el algoritmo de backpropagation como el encargado de optimizar la función de perdida para mejorar las predicciones de una red neuronal. Este algoritmo se encarga de calcular las derivadas (o gradientes) de los parametros W y b para saber como estos parametros afectan al resultado de la función de perdida, esta es una definición que puede ser usada para explicar el algoritmo, pero para ser más precisos, la optimización de una red neuronal se divide en dos partes, la primera es el algoritmo de backpropagation, como mencione este algoritmo se encarga de ver como los valores de W y de b afectan al resultado de la función de perdida y la segunda parte es el algoritmo de optimización, este se encarga de optimizar la red neuronal y cambiar los valores de W y de b conforme pasan los ciclos (o epochs). Existen diferentes algoritmos de optimización, unos son mejores que otros, aunque depende del tipo de problema se este resolviendo. Este algoritmo es un parametro de la red neuronal llamado optimizer. Los algoritmos tienen un comportamiento parecido que varia en algunos calculos pero la idea general es encontrar el global minimum o el mínimo global de la función de perdida, lo que hace el algoritmo es descender por la función hasta llegar a este punto donde la función se encuentra optimizada, esto se logra con ayuda de las derivadas que indican que camino se tiene que seguir.
Optimizer
Como lo mencione antes existen diferentes tipos de algoritmos de optimización el más famoso se llama gradient descent y el más usado se llama Adam. No entrare en detalle de como funcionan pero es importante saber para que sirven y que funcionalidad tienen dentro de una red neuronal. Este es considerado un hiperparametro.
Learning rate
Este hiperparametro indica que tan largo sera el camino que tome el algoritmo de optimización. Si el valor es muy pequeño la actualización se puede quedar atrapada en un minimo local y los valores de W y b no cambiarian correctamente, igualmente la red neuronal tardara mucho más tiempo en optimizar. Por otro lado si los valores son muy altos la actualización puede pasarse del punto perfecto que sería el minimo global y nunca encontrarlo y aunque el aprendizaje sea más rapido nunca llegara al minimo global.
Lost function
La función de perdida, también conocida como función de costo, es la función que nos dice que tan buena es la red neuronal, un resultado alto indica que la red neuronal tiene un desempeño pobre y un resultado bajo indica que la red neuronal esta haciendo un buen trabajo. Esta es la función que optimizamos o minimizamos cuando realizamos el backpropagation.
Existen varias funciones matematicas que pueden usarse, la elección de una depende del problema que se esta resolviendo. Algunas de estas funciones son:
Cross Entropy
−(y log(p) + (1 − y)log(1 − p))
Esta función se usa para problemas de clasificación
Mean Squared Error
(p - y) ** 2
Esta función se usa para problemas de regresión.
Epoch
Este es el numero de veces que se ejecutaran los algoritmos de forwardpropagation y backpropagation. En cada ciclo (epoch) todos los datos de entrenamiento pasan por la red neuronal para que esta aprenda sobre ellos, si existen 10 ciclos y 1000 datos, cada ciclo los 1000 datos pasaran por la red neuronal. Si se especifica el parametro batch size cada ciclo (epoch) tendra más ejecuciones internas, estas ejecuciones se llaman iteraciones, si tenemos un batch size de 100, se tendran 10 iteraciones para completar un ciclo, en cada iteración se ejecutan los algoritmos de forwardpropagation y backpropagation, de esta manera la red neuronal actualiza más veces los parametros W y b. Esta variable también es un hiperparametro.
Batch size
Es el numero de datos que tiene cada iteración de un ciclo (epoch), esto es util porqué la red neuronal actualiza los parametros W y b más veces, también cuando se tienen grandes cantidades de datos se necesitan computadoras con más memoria y la red neuronal tarda más en ejecutar cada ciclo, si dividimos los ciclos en iteraciones con un numero de datos más pequeño ya no es necesario cargar todos los datos en la memoria al mismo tiempo y la red neuronal se entrena más rapido.
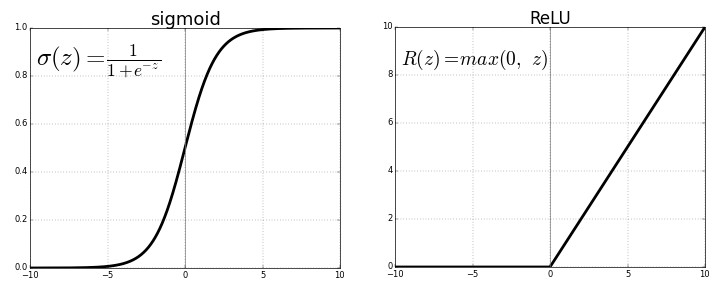
Activation function
Las funciones de activación se encuentran en cada neurona de una red neuronal y la utilidad más importante que tienen es indicar cuando una neurona se activa o se apaga, dependiendo de la función de activación que se use, esta tendra ciertos limites, recordemos que primero se calcula la función Z = WX + b y el resultado de esta función se le pasa a la función de activación, esta ultima busca si los datos tienen los patrones que busca la neurona o no los tiene.
Las funciones de activación más usadas son sigmoid y relu
Weight
Los pesos son parametros importantes en una red neuronal, estos parametros se multiplicaran con los datos de entrada X y con las salidas de las neuronas de la capa anterior A, cada parametro W es diferente para cada neurona ya que en estos parametros se guardan patrones que la neurona aprendió sobre los datos.
Bias
Bias b es un parametro que ayuda a mover la línea que divide los datos de cada neurona, si el valor de b es cero, la línea pasa por el origen, dependiendo del numero que tenga este paremetro es por donde pasara la línea que divide a los datos.
hyperparameters
Son los parametros que modificamos manualmente en una red neuronal. Son muy importantes para lograr un buen desempeño y nuestro trabajo es encontrar los que mejor se adapten al problema que estamos resolviendo. Algunos ejemplos son:
- Activation function
- Batch size
- Epoch
- Lost function
- Learning rate
- Optimizer
- Layer (numero de capas)
No hay comentarios:
Publicar un comentario